Oracle uses its buffer cache for caching or storing recently accessed table blocks. This helps Oracle to access the same blocks faster if they are required again. Since the buffer cache resides in memory and memory is expensive this cache size is always limited. Oracle uses a LRU (Least Recently Used) algorithm to keep the most recently access blocks in memory. It is a complex algorithm for buffer cache management, but lets simplify it by saying oracle keeps a simple queue which holds the most recently used data at the hot end. As we query more and more data, existing data in the queue is pushed backwards and finally moves out of the queue.
When you query some data which had already been moved out of cache, oracle finds this data is no longer in memory and it goes for physical reads (from disks) and this is an expensive and time consuming operation.
One of the big issue with this kind of a cache is, if you query a big table most of the queue can be replaced by the data from that table alone and all subsequent queries may go for physical reads. Oracle can’t allow this and such reads bypass the buffer cache to maintain its balance. Oracle usually avoids moving the blocks of huge tables into buffer cache by using direct path reads/writes which uses the PGA (Program Global Area) which is not a shared memory area. Since PGA is not shared among the users, such caching of data is not useful for other users of the database. And this may lead to extensive physical read operations.
Recent versions of oracle (12c) is trying to overcome this issue by identifying the big tables in the database and caching data from those tables effectively. This is done by reserving a part of buffer cache for storing big tables.
Let’s test this feature by creating couple of big tables (> 1 Million rows).
SQL> create table my_test_tbl
2 (Name varchar2(100),
3 Emp_No integer,
4 Dept_no integer);
Table created.
SQL> insert into my_test_tbl
2 select 'John Doe', level, mod(level,10)
3 from dual
4 connect by level <= 1000000; SQL> commit;
Commit complete.
SQL> select count(*) from my_test_tbl;
COUNT(*)
----------
1000000
We need to analyze the table, so that the metadata will be updated.
SQL> analyze table my_test_tbl compute statistics;
We will have to set a parameter at system level so that a part of the buffer cache (40% in our case) will be allocated for caching big tables. First , lets check the size of buffer cache allocated for this database.
SQL> select component, current_size/power(1024,3) current_size_GB from v$memory_dynamic_components
2 where component = 'DEFAULT buffer cache'
COMPONENT CURRENT_SIZE_GB
-------------------- ---------------
DEFAULT buffer cache 1.546875
We have 1.5GB of buffer cache, let’s allocate 40% of this for caching big tables.
SQL> show parameter big_table
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_big_table_cache_percent_target string 0
SQL> alter system set db_big_table_cache_percent_target = 40;
System altered.
SQL> show parameter big_table
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_big_table_cache_percent_target string 40
Now, if we query the table it will be cached in to the big table cache.
SQL> select count(*) from my_test_tbl;
COUNT(*)
----------
1000000
Please make note that we don’t have to restart the DB for modifying this parameter. Lets check the caching of the table and how much of it is cached,
SQL> select * from V$BT_SCAN_CACHE;
 Clearly shows 40% is reserved for big tables.
Clearly shows 40% is reserved for big tables.
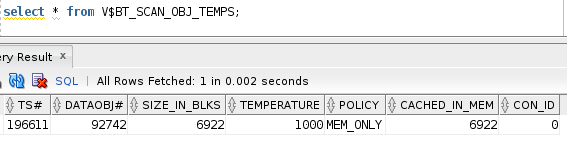
We have already queried the table once and oracle had identified that the table is indeed a big one. Now we have table in cache, we can check the size of the table on disk and how much of it is cached. Since the V$BT_SCAN_OBJ_TEMPS table contains the object id we can join it with DBA_OBJECTS and find out the table name. Once we have the table name DBA_TABLES will give us the size of the table on disk (blocks).
SQL> select object_name from dba_objects where object_id = 92742
OBJECT_NAME
--------------------
MY_TEST_TBL
SQL> column table_name format a20
select table_name, blocks from dba_tables
where table_name = 'MY_TEST_TBL';
TABLE_NAME BLOCKS
-------------------- ----------
MY_TEST_TBL 6922
The whole table is cached now and the temperature is set to 1000, if we use this table more and more the temperature of this table will go up making it hot. Below code snippet will query my_test_tbl 10,000 times and this will help us to increase the temperature of the table.
SQL> declare
2 l_count integer;
3 begin
4 for i in 1..10000
5 loop
6 select count(*) into l_count from my_test_tbl;
7 end loop;
8 end;
9 /
PL/SQL procedure successfully completed.
Check the V$BT_SCAN_OBJ_TEMPS table again to see if the temperature value has gone up.
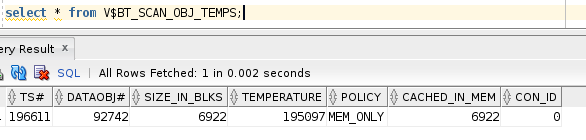
We can see the temperature of the table has gone up because of the frequent querying, now we are creating another table and see if that is also getting cached. We will have 2 million records in this table.
SQL> create table my_test_tbl2
2 as select * from MY_TEST_TBL;
SQL> insert into my_test_tbl2 select * from my_test_tbl;
1000000 rows created.
SQL> analyze table my_test_tbl2 compute statistics;
Table analyzed.
SQL> select table_name, blocks from dba_tables
where table_name = 'MY_TEST_TBL2';
TABLE_NAME BLOCKS
-------------------- ----------
MY_TEST_TBL2 6224
SQL> select count(*) from MY_TEST_TBL2;
COUNT(*)
----------
2000000
We can see the new table in cache with initial temperature value of 1000.
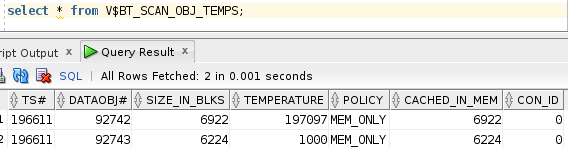
Lets run the snippet again to query the new table, this time we will query only 100 times.
Query V$BT_SCAN_OBJ_TEMPS again to see the new temperature value of second table.
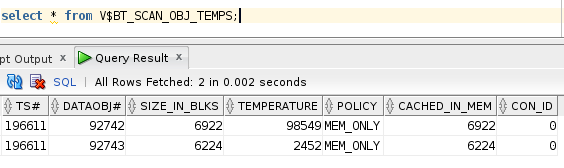
This temperature value helps oracle to prioritize tables in memory and identify which table is frequently queried. Based on this information oracle decides which table stays in memory and which table has to move out.
We have to remember currently we don’t have any option to move individual tables to the cache. It is completely automated and done by Oracle’s discretion. Our table may or may not be moved to this cache, but if you have big tables which you think may get benefited from this option then you can check this option.